Spambook
Use classification to predict whether a message is spam or not
Sklearn RegEx FlaskAbout
The goal was to develop a classifying spam messages.
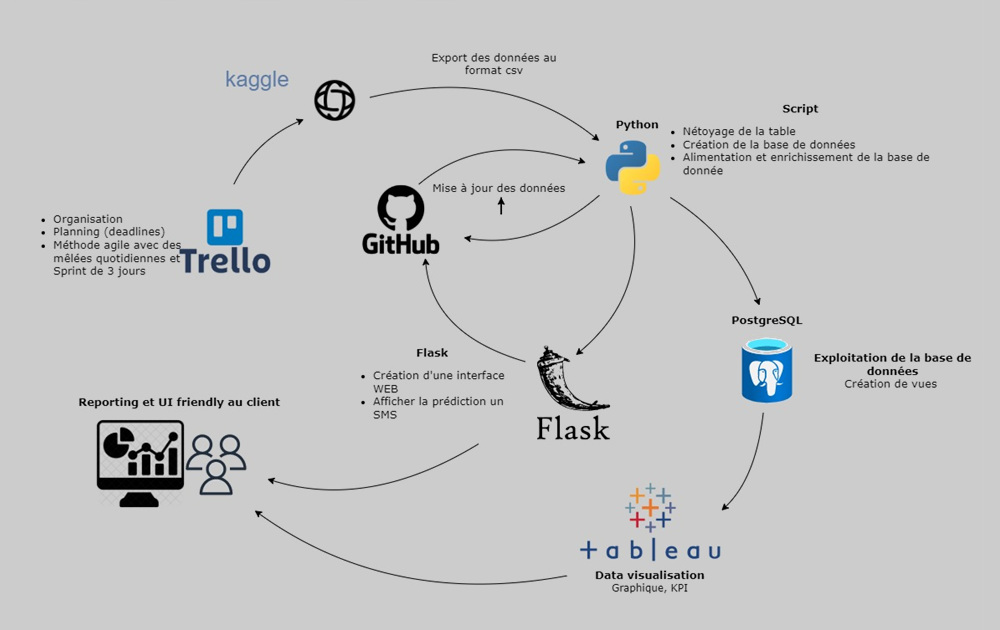
The project began with data cleaning. I removed duplicate messages to prepare the dataset for analysis.
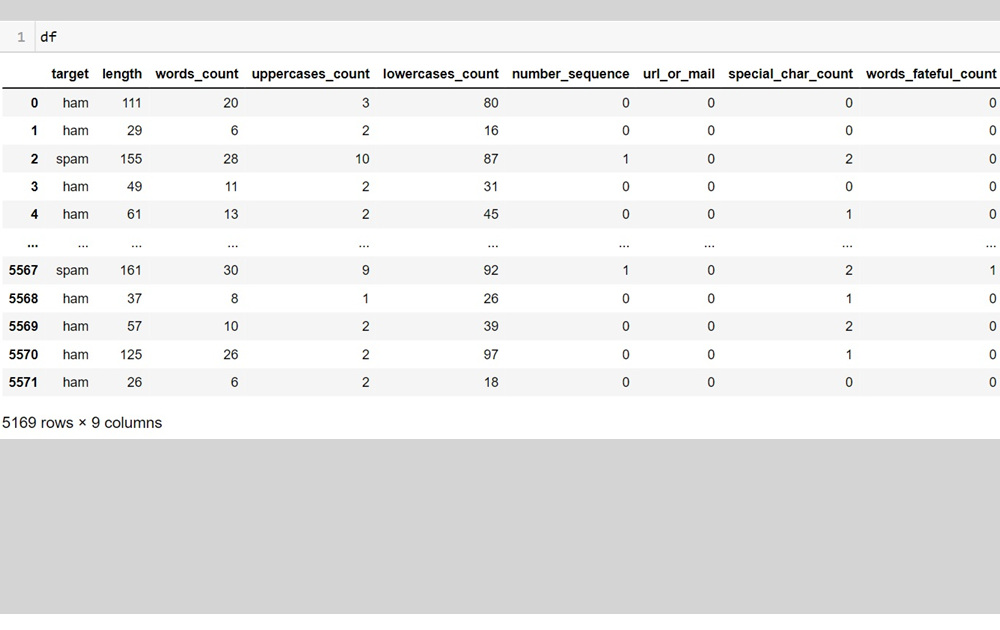
Next, I focused on feature extraction, using regular expressions (RegEx). I engineered several features such as:
- The total number of words in a message
- The presence of a phone number
- The presence of a URL
- The presence of an email address
- The total number of special characters
- etc...
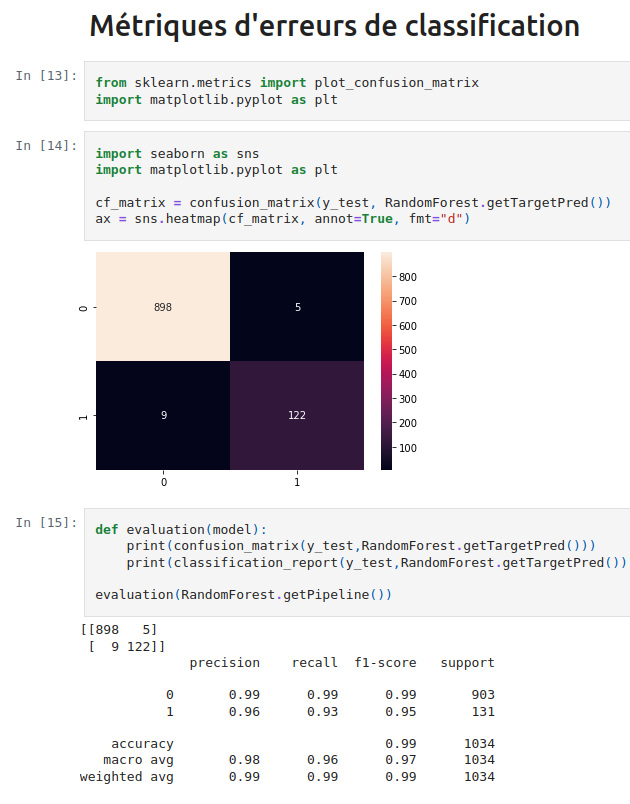
Once the features were extracted, I normalized the data to improve the performance of the machine learning algorithms. Then I built a machine learning pipeline, where I tested several models like DecisionTreeClassifier or RandomForestClassifier and used GridSearchCV to find the best parameters for our models. These models were trained to classify messages as either "spam" or "ham" (non-spam).
To make the project more interactive and accessible, I developed a Flask application that allows users to input a message and get a real-time classification result. This project helped me apply the full machine learning workflow, from preprocessing to model deployment.
Screenshots :